1. Giới thiệu về hệ thống khuyến nghị (Recommender System – RS)
Hệ thống khuyến nghị (Recommender System – RS) đã xuất hiện từ giữa những năm 90 của thế kỷ XX để giải quyết vấn đề quá tải thông tin. RS thường được định nghĩa là một công cụ hay hệ thống phần mềm đóng vai trò như một trợ lý, cung cấp cho người dùng các đề xuất được cá nhân hóa dựa trên sở thích và mối quan tâm trước đây của họ. Ngày nay, các hệ thống khuyến nghị là một phần quan trọng không thể thiếu trong hầu hết các hệ thống hiện đại, chẳng hạn trong các nền tảng Thương mại điện tử như Amazon, E-Bay, Lazada, Tiki, Shopee, ..vv..
2. Phân loại các phương pháp khuyến nghị
Trong nhiều năm, các phương pháp khuyến nghị khác nhau đã được đề xuất và có thể được phân loại thành: Phương pháp bộ lọc cộng tác (Collaborative filtering – CF), Phương pháp dựa trên nội dung (Content based filtering – CBF) và Phương pháp kết hợp/ tổng hợp (Hybrid/Ensemble). CF sử dụng xếp hạng của khách hàng để phân loại người dùng/hoặc sản phẩm trong các nhóm theo mức độ giống nhau của họ/chúng. Các đề xuất sau đó được suy ra bằng cách tính đến xếp hạng của những người dùng trong cùng một nhóm, hoặc item trong cùng một nhóm (Hình 1a). Ngược lại, hệ thống khuyến nghị dựa trên nội dung sẽ tính toán các đề xuất theo tính năng của các mặt hàng mà người dùng ưa thích trong quá khứ – chẳng hạn như tiêu đề phim, diễn viên hoặc thể loại của phim (Hình 1b). Hiệu suất của mỗi thuật toán khuyến nghị đơn lẻ này, tuy nhiên, đều có giới hạn và mỗi thuật toán có điểm mạnh và điểm yếu riêng [1]. Do đó, hai phương pháp tiếp cận CF và CBF có thể được tích hợp một cách tự nhiên vào một hệ thống khuyến nghị kết hợp / tổng hợp. Trong cuộc khảo sát của Borràs và cộng sự, 2014 [2], có thể nhận thấy xu hướng ngày càng tăng trong việc khai thác các kỹ thuật lọc khuyến nghị kể từ năm 2012, chủ yếu trong các hệ thống lai. Từ năm 2008 đến năm 2011, chỉ có 25% hệ thống sử dụng phương pháp này, trong khi từ năm 2012, tỷ lệ này đã tăng lên 75%.

Hình 1. Ví dụ về (a) bộ lọc cộng tác – Collaborative filtering, (b) bộ lọc dựa trên nội dung – Content based filtering [1]
3. Thách thức đối với các hệ thống khuyến nghị trong môi trường dữ liệu lớn
Điều đáng chú ý là trong khi ngày càng có nhiều nỗ lực để nghiên cứu các phương pháp mới cho RS, không có nhiều công trình đã điều chỉnh RS trong bối cảnh dữ liệu lớn – Big data. Dữ liệu lớn đặt ra nhiều thách thức trong việc lưu trữ, tích hợp và quản lý dữ liệu, và quan trọng không kém đó là làm sao trích xuất thông tin cần thiết một cách hiệu quả trong khối lượng lớn dữ liệu như vậy. Không ngạc nhiên là mặc dù một số phương pháp khuyến nghị đã chứng minh hiệu suất tốt cho các tập dữ liệu quy mô nhỏ, nhưng rất khó để áp dụng chúng trong bối cảnh Dữ liệu lớn (Hình 2). Một số vấn đề mà hệ thống khuyến nghị sẽ phải đối mặt trong bối cảnh dữ liệu lớn có thể kể đến như:
- Số lượng lớn người dùng/sản phẩm;
- Dữ liệu thưa – xảy ra khi người dùng đã không đánh giá phần lớn các bộ phim;
- Khuyến nghị cho người dùng mới/ các sản phẩm mới chưa từng xuất hiện trước đây;
- Tốc độ thực thi của hệ thống khuyến nghị.
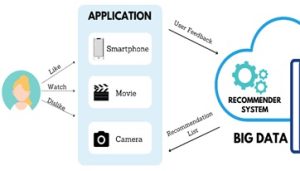
Hình 2. Hệ thống khuyến nghị trong bối cảnh Dữ liệu lớn [3]
4. Triển vọng nghiên cứu
Trong kỷ nguyên dữ liệu lớn, chúng ta đã thấy sự gia tăng theo cấp số nhân của khối lượng dữ liệu trong những thập kỷ gần đây. Sự tiến bộ nhanh chóng của công nghệ và việc sử dụng ngày càng nhiều các tương tác trực tuyến đã dẫn đến sự bùng nổ dữ liệu. Điều này đã truyền cảm hứng rất nhiều cho các nhà nghiên cứu để cải thiện hiệu suất của các hệ thống khuyến nghị hoặc điều chỉnh chúng trong bối cảnh dữ liệu lớn để xử lý các bộ dữ liệu quy mô lớn. Vào năm 2013, [4] đã sử dụng dữ liệu thừa ma trận và rừng ngẫu nhiên trên các hệ thống khuyến nghị dữ liệu lớn, tập trung vào việc chia vấn đề dữ liệu lớn thành các bài toán con nhỏ hơn để tăng tốc quá trình. Vào năm 2015, [5] đã giải thích cách sử dụng hệ thống khuyến nghị với dữ liệu lớn. Bài báo đề xuất sử dụng CF, CBF và lọc kết hợp trên khuôn khổ Hadoop. Kết quả của họ cho thấy rằng với các thuật toán được áp dụng đúng cách, thời gian chạy của chương trình chỉ tăng lên một chút trong khi lượng dữ liệu được tăng lên đáng kể. Vào năm 2018, [6] đã đánh giá tác động của Dữ liệu lớn đến chất lượng đề xuất bằng cách thử nghiệm hiệu suất của mô hình hồi quy trên ví dụ về Tìm kiếm trên Internet.
Ngoài ra, việc sử dụng phân cụm trong quy trình đề xuất cũng đã nhận được sự chú ý của một số nhà nghiên cứu [7], [8], [9], [10]. Trong nghiên cứu gần đây của chúng tôi [3], chúng tôi đã đề xuất một phương pháp khuyến nghị làm việc trên môi trường Big data dựa trên phân cụm. Nó có thể giải quyết vấn đề dữ liệu thưa và sự xuất hiện của các sản phẩm mới. Ngoài ra, tốc độ huấn luyện và dự đoán đều nhanh. Ý tưởng chính đằng sau kỹ thuật này là một chiến lược chia để trị trong đó số lượng người dùng có thể được nhóm thành các nhóm khác nhau dựa trên sở thích của họ. Dự đoán sau đó được thực hiện trực tiếp theo sở thích của mỗi người dùng cũng tầm quan trọng của họ trong cụm. Trên cơ sở các kết quả đã đạt được, chúng tôi hy vọng rằng trong thời gian tới sẽ tiếp tục phát triển các bài toán khuyến nghị trên môi trường dữ liệu lớn, để không những đẩy nhanh thời gian thực thi mà còn nâng cao được độ chính xác và chất lượng của khuyến nghị.
TÀI LIỆU THAM KHẢO
| [1] | H. Q. Do, T. H. Le and B. Yoon, “Dynamic Weighted Hybrid Recommender Systems,” in International Conference on Advanced Communication Technology, 2020. |
| [2] | J. Borràs, A. Moreno and A. Valls, “Intelligent tourism recommender systems: A survey,” Expert Systems with Applications, vol. 41, no. 16, pp. 7370-7389, 2014. |
| [3] | H.-Q. Do, T.-A. Nguyen, Q.-A. Nguyen, T.-H. Nguyen, V.-V. Vu and C. Le, “A Fast Clustering-based Recommender System for Big Data,” in 24th International Conference on Advanced Communication Technology (ICACT), 2022. |
| [4] | B. A. Hammou, A. A. Lahcenab and S. Mouline, “An effective distributed predictive model with Matrix factorization and random forest for Big Data recommendation systems,” Expert Systems with Applications, vol. 137, pp. 253-265, 2019. |
| [5] | J. P. Verma, B. Patel and A. Patel, “Big Data Analysis: Recommendation System with Hadoop Framework,” International Conference on Computational Intelligence & Communication Technology, pp. 92-96, 2015. |
| [6] | S. Maximilian, G. Sapi and S. Lorincz, “The effect of big data on recommendation quality: The example of internet search,” Econstor, no. 284, 2018. |
| [7] | J. Zhang, Y. Lin, M. Lin and J. Liu, “An effective collaborative filtering algorithm based on user preference clustering,” Applied Intelligence, vol. 45, 2016. |
| [8] | L. Zhang, X. Sun, J. Cheng and Z. Li, “Reliable Neighbors-Based Collaborative Filtering for Recommendation Systems,” in Neural Computing for Advanced Applications, 2020, pp. 60-71. |
| [9] | F. Xie, M. Xu and Z. Chen, “RBRA: a simple and efficient rating-based recommender,” in International Conference on Advanced Information Networking and Applications Workshops, 2012. |
| [10] | D. Zhang, C. Hsu, M. Chen, Q. Chen, N. Xiong and J. Lloret, “Cold-Start Recommendation Using Bi-Clustering and Fusion for Large-Scale Social Recommender Systems,” IEEE Trans. Emerg. Topics Comput., vol. 2, no. 2, pp. 239-250, 2014. |
Phòng CSDL&HTTT (email liên hệ: quandh@vnu.edu.vn (Đỗ Hồng Quân))



