1. Introduction to the Recommender System (RS)
Recommender System ( RS) has appeared since the mid 90s of the twentieth century to solve the problem of information overload. RS generally defined as a tool or system software that acts as an assistant, providing users with personalized recommendations based on their past interests and preferences. Today, recommendation systems are an important and indispensable part of most modern systems, for example in e-commerce platforms like Amazon, E-Bay, Lazada, Tiki, Shopee, .. etc..
2. Classification of recommended methods
Over the years, different recommendation methods have been proposed and can be classified as: Collaborative filtering ( CF) methods, Content based filtering ( CBF) methods and Hybrid/Ensemble method. CF uses customer ratings to classify users/or products in groups according to their/them similarity. Recommendations are then inferred by taking into account the ratings of users in the same group, or items in the same group (Figure 1a). In contrast, a contentbased recommendation systemwill compute recommendations according to the features of the items the user liked in the past – such as the movie title, actors or genre of the movie (Figure 1b ). The performance of each of these single recommended algorithms , however, is limited, and each has its own strengths and weaknesses [1]. Therefore, the two approaches CF and CBF can be spontaneously integrated into a combined /synthetic recommendation system. In the survey by Borràs et al., 2014 [2], an increasing trend can be observed in exploiting recommendation filtering techniques since 2012, mainly in hybrid systems. From 2008 to 2011, only 25% of systems used this method, while from 2012 this percentage increased to 75%.

Image 1. Examples of (a) Collaborative filtering, (b) Content based filtering [1]
3. Challenges for recommendation systems in big data environment
It is worth noting that while there are increasing efforts to research new methods for RS, not many works have adapted RS in the context of big data – Big data. Big data poses many challenges in storing, integrating and managing data, and no less important is how to extract the needed information efficiently in such large volumes of data. Not surprisingly is although some of the recommended methods have demonstrated good performance for small-scale data sets, it is difficult to apply them in the context of lớnBig Data (Figure 2). Some of the problems that the recommendation system will face in the context of big data can be mentioned as:
- Large number of users/products;
- Sparse data – occurs when users have not rated the majority of movies;
- Recommendations for new users/new products that have not appeared before;
- The execution speed of the recommendation system.
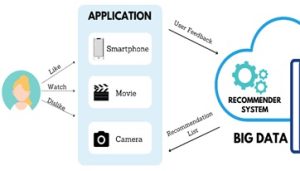
Image 2. Recommendation systems in the context of Big Data [3]
4. Research prospects
In the era of big data, we have seen an exponential increase in the volume of data in recent decades. The rapid advancement of technology and the increasing use of online interactions have led to an explosion of data. This has greatly inspired researchers to improve the performance of recommendation systems or adapt them in big data contexts to handle large-scale datasets. In 2013, [4] used matrix redundancy and random forests on big data recommendation systems, focusing on breaking the big data problem into smaller subproblems to speed up the process. submit. In 2015, [5] explained how to use a recommendation system with big data. The paper proposes to use CF, CBF and combined filtering on the Hadoop framework. Their results show that with properly applied algorithms, the running time of the program is only increased slightly while the amount of data is increased significantly. In 2018, [6] assessed the impact of Big Data on recommendation quality by testing the performance of the regression model on the Internet Search example.
In addition, the use of clustering in the proposed process has also received the attention of some researchers [7], [8], [9], [10]. In our recent study [3], we have proposed a recommended method working on Big data environment based on clustering. It can solve the problem of data sparse and the arrival of new products. In addition, the training and prediction speed are both fast. The main idea behind this technique is a divide-and-conquer strategy in which the number of users can be grouped into different groups based on their preferences. Predictions then are made directly according to each user’s preferences as well as their importance in the cluster. Based on the obtained results, we hope that in the coming time, we will continue to develop recommended problems in the big data environment, to not only speed up the execution time but also improve the accuracy and quality of recommendations.
DOCUMENTS
| [1] | H. Q. Do, T. H. Le and B. Yoon, “Dynamic Weighted Hybrid Recommender Systems,” in International Conference on Advanced Communication Technology, 2020. |
| [2] | J. Borràs, A. Moreno and A. Valls, “Intelligent tourism recommender systems: A survey,” Expert Systems with Applications, vol. 41, no. 16, pp. 7370-7389, 2014. |
| [3] | H.-Q. Do, T.-A. Nguyen, Q.-A. Nguyen, T.-H. Nguyen, V.-V. Vu and C. Le, “A Fast Clustering-based Recommender System for Big Data,” in 24th International Conference on Advanced Communication Technology (ICACT), 2022. |
| [4] | B. A. Hammou, A. A. Lahcenab and S. Mouline, “An effective distributed predictive model with Matrix factorization and random forest for Big Data recommendation systems,” Expert Systems with Applications, vol. 137, pp. 253-265, 2019. |
| [5] | J. P. Verma, B. Patel and A. Patel, “Big Data Analysis: Recommendation System with Hadoop Framework,” International Conference on Computational Intelligence & Communication Technology, pp. 92-96, 2015. |
| [6] | S. Maximilian, G. Sapi and S. Lorincz, “The effect of big data on recommendation quality: The example of internet search,” Econstor, no. 284, 2018. |
| [7] | J. Zhang, Y. Lin, M. Lin and J. Liu, “An effective collaborative filtering algorithm based on user preference clustering,” Applied Intelligence, vol. 45, 2016. |
| [8] | L. Zhang, X. Sun, J. Cheng and Z. Li, “Reliable Neighbors-Based Collaborative Filtering for Recommendation Systems,” in Neural Computing for Advanced Applications, 2020, pp. 60-71. |
| [9] | F. Xie, M. Xu and Z. Chen, “RBRA: a simple and efficient rating-based recommender,” in International Conference on Advanced Information Networking and Applications Workshops, 2012. |
| [10] | D. Zhang, C. Hsu, M. Chen, Q. Chen, N. Xiong and J. Lloret, “Cold-Start Recommendation Using Bi-Clustering and Fusion for Large-Scale Social Recommender Systems,” IEEE Trans. Emerg. Topics Comput., vol. 2, no. 2, pp. 239-250, 2014. |
Phòng CSDL&HTTT (email liên hệ: quandh@vnu.edu.vn (Đỗ Hồng Quân))



